 HERMES
HERMES

Long Movies (MovieChat)
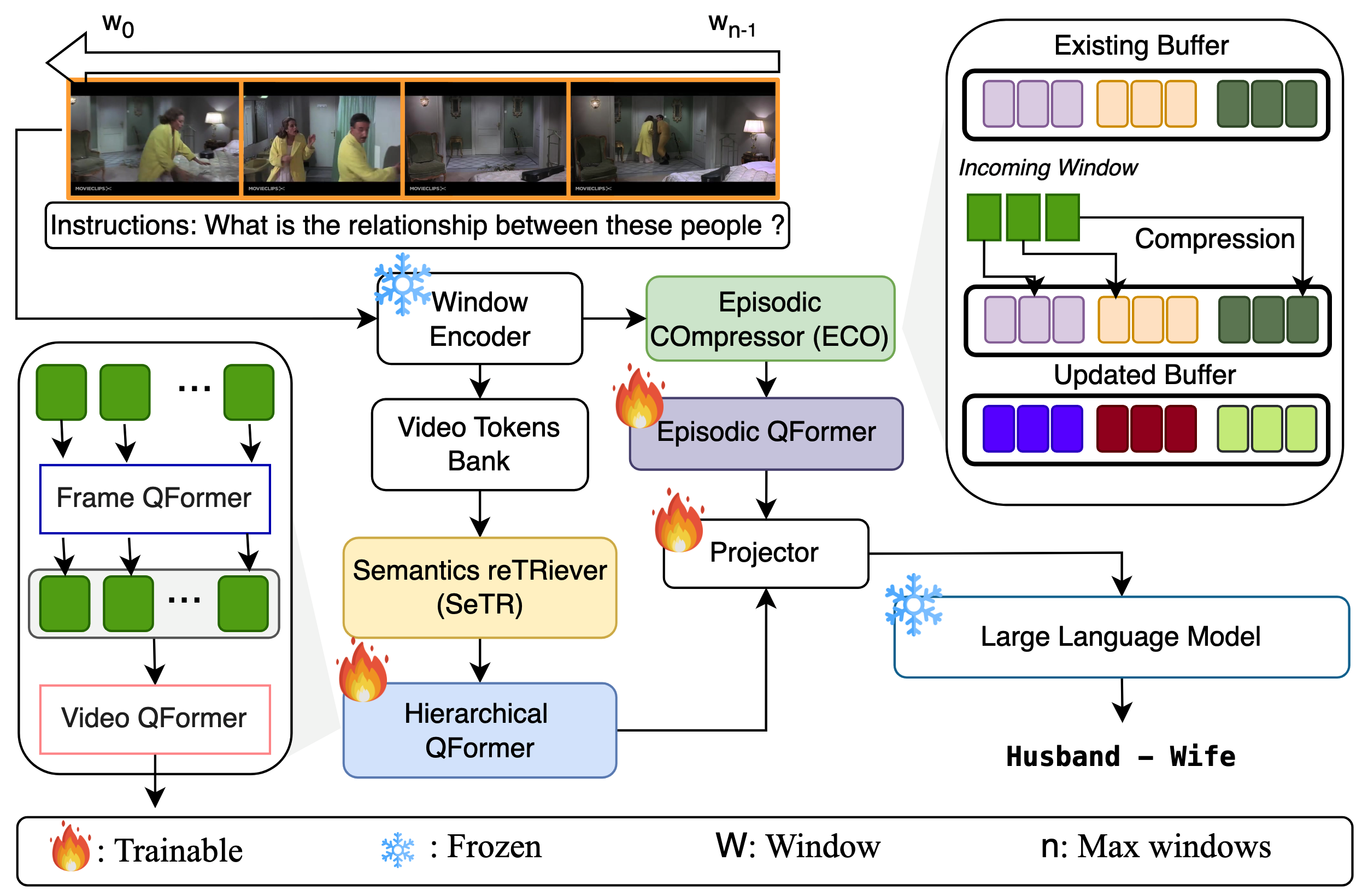
Long-form video understanding presents unique challenges that extend beyond traditional short-video analysis approaches, particularly in capturing long-range dependencies, processing redundant information efficiently, and extracting high-level semantic concepts.
To address these challenges, we propose a novel approach that more accurately reflects human cognition. This paper introduces HERMES: temporal-coHERent long-forM understanding with Episodes and Semantics, featuring two versatile modules that can enhance existing video-language models or operate as a standalone system. Our Episodic COmpressor (ECO) efficiently aggregates representations from micro to semi-macro levels, reducing computational overhead while preserving temporal dependencies. Our Semantics ReTRiever (SeTR) enriches these representations with semantic information by focusing on broader context, dramatically reducing feature dimensionality while preserving relevant macro-level information. We demonstrate that these modules can be seamlessly integrated into existing SOTA models, consistently improving their performance while reducing inference latency by up to 43% and memory usage by 46%. As a standalone system, HERMES achieves state-of-the-art performance across multiple long-video understanding benchmarks in both zero-shot and fully-supervised settings.
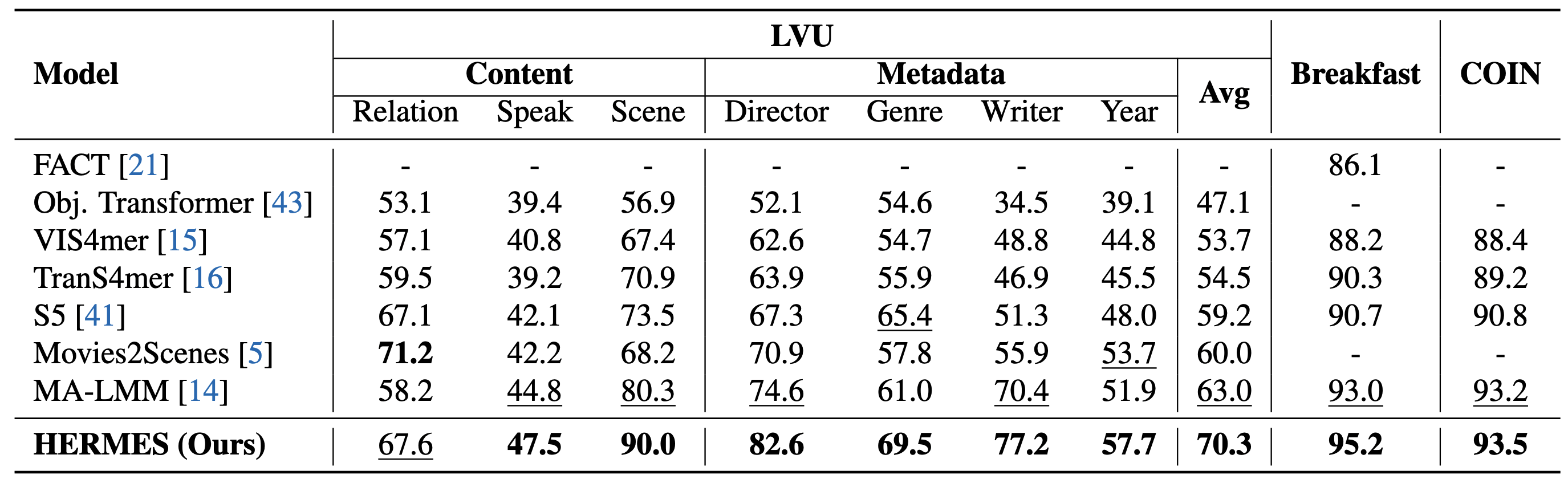
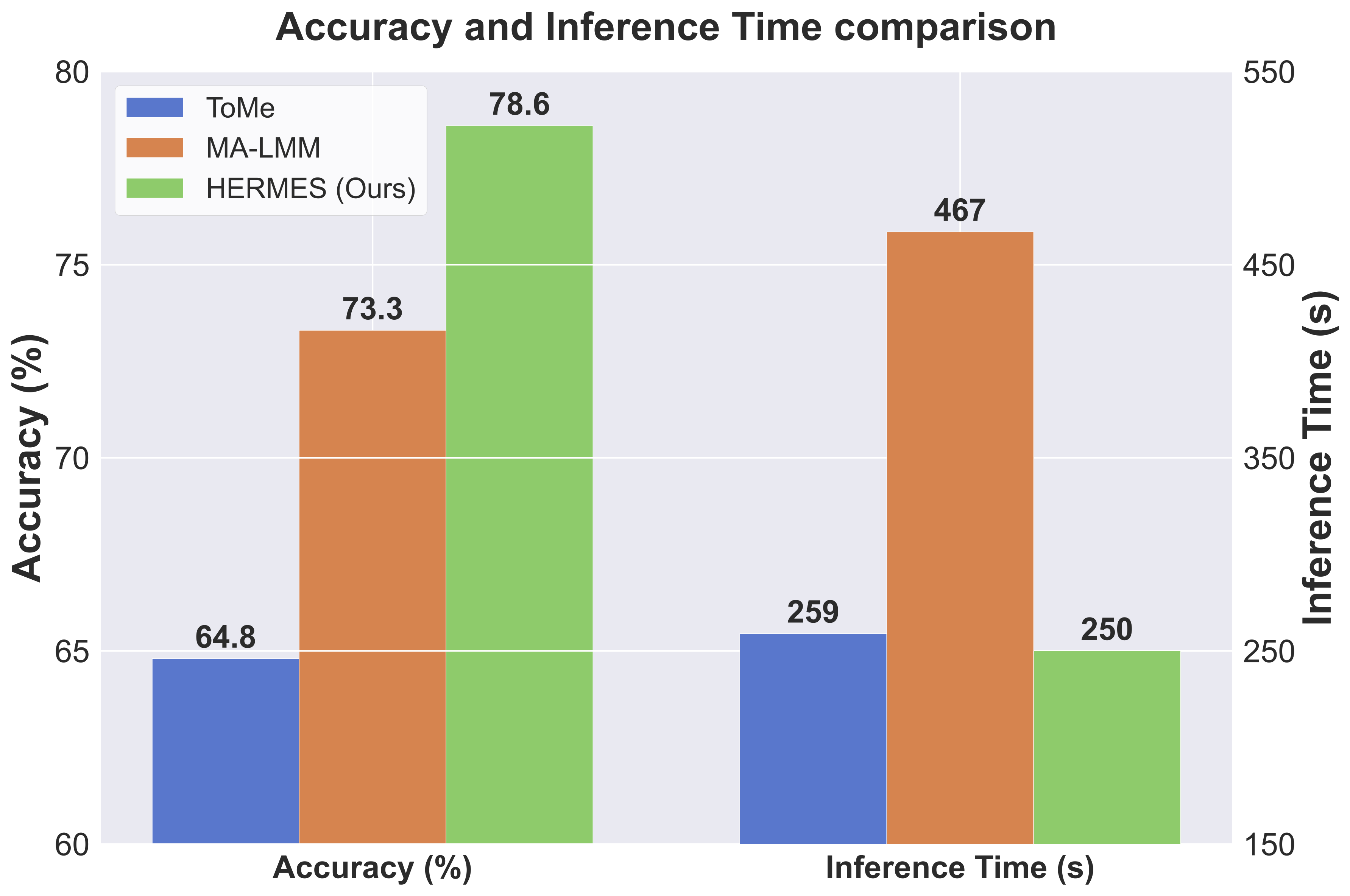
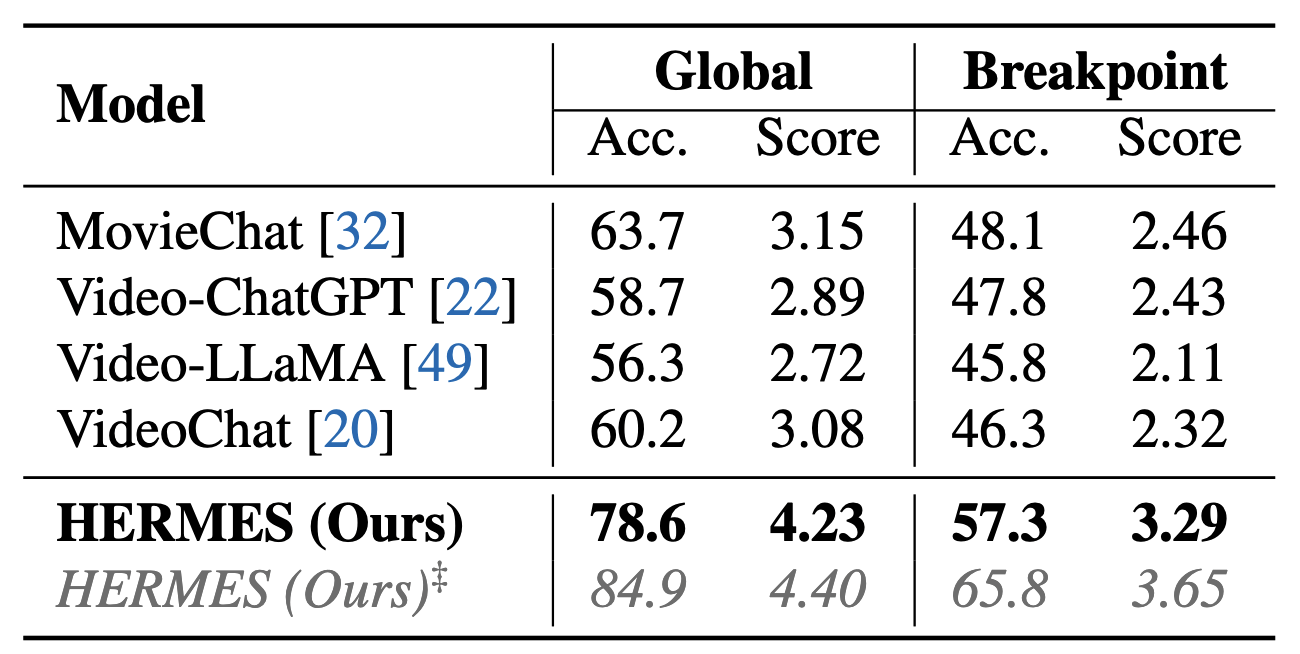
No tradeoffs, improvements across the board.

HERMES excels at fine-grained understanding of arbitrarily long videos. Furthermore, it has the rare quality of knowing when it doesn't know.

HERMES can identify animal species, accurately count them. It can also determine peoples' relationships by watching them interact across thousands of frames.

@misc{faure2024hermestemporalcoherentlongformunderstanding,
title={HERMES: temporal-coHERent long-forM understanding with Episodes and Semantics},
author={Gueter Josmy Faure and Jia-Fong Yeh and Min-Hung Chen and Hung-Ting Su and Shang-Hong Lai and Winston H. Hsu},
year={2024},
eprint={2408.17443},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2408.17443},
}